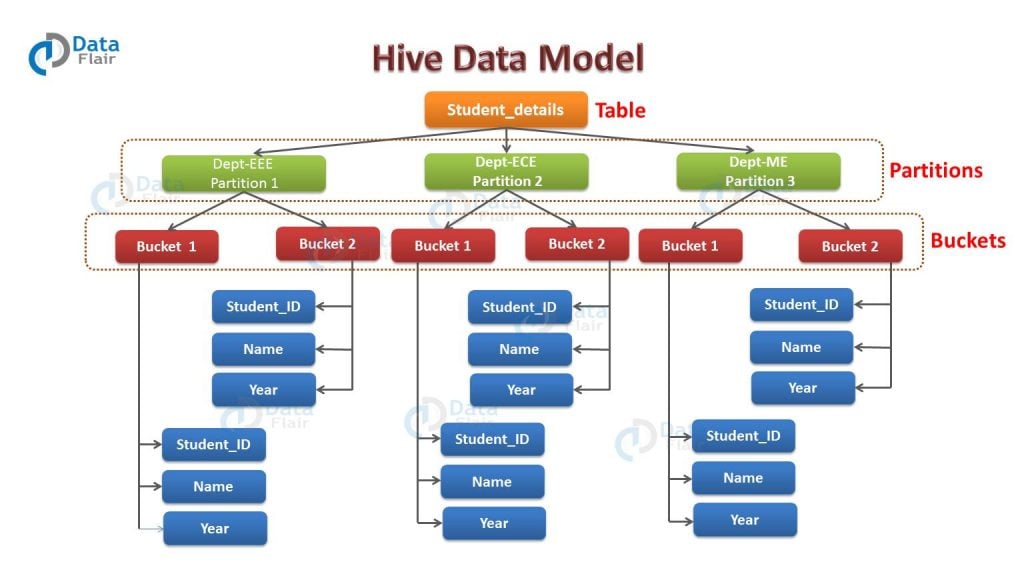
Partition And Bucketing In Hive With Example. Let’s understand it with an example: hive partitions & buckets with example. Tables, partitions, and buckets are the parts of hive data modeling. Partition is helpful when the table has one or more partition keys. It is used for distributing the load horizontally. hive partitioning separates data into smaller chunks based on a particular column, enhancing query. bucketing is another technique for decomposing data sets into more manageable parts. partitioning in hive is conceptually very simple: Hive partitions is a way to organizes tables into partitions by dividing tables into different parts based on partition keys. hive bucketing is a way to split the table into a managed number of clusters with or without partitions. apache hive allows us to organize the table into multiple partitions where we can group the same kind of data together. With partitions, hive divides(creates a. We define one or more columns to partition the data on, and then for each unique combination. For example, suppose a table using date as the top.
from data-flair.training
With partitions, hive divides(creates a. hive bucketing is a way to split the table into a managed number of clusters with or without partitions. Partition is helpful when the table has one or more partition keys. hive partitioning separates data into smaller chunks based on a particular column, enhancing query. Hive partitions is a way to organizes tables into partitions by dividing tables into different parts based on partition keys. It is used for distributing the load horizontally. Tables, partitions, and buckets are the parts of hive data modeling. We define one or more columns to partition the data on, and then for each unique combination. partitioning in hive is conceptually very simple: apache hive allows us to organize the table into multiple partitions where we can group the same kind of data together.
Hive Partitioning vs Bucketing Advantages and Disadvantages DataFlair
Partition And Bucketing In Hive With Example bucketing is another technique for decomposing data sets into more manageable parts. Let’s understand it with an example: With partitions, hive divides(creates a. Partition is helpful when the table has one or more partition keys. For example, suppose a table using date as the top. partitioning in hive is conceptually very simple: bucketing is another technique for decomposing data sets into more manageable parts. Tables, partitions, and buckets are the parts of hive data modeling. We define one or more columns to partition the data on, and then for each unique combination. It is used for distributing the load horizontally. apache hive allows us to organize the table into multiple partitions where we can group the same kind of data together. Hive partitions is a way to organizes tables into partitions by dividing tables into different parts based on partition keys. hive partitioning separates data into smaller chunks based on a particular column, enhancing query. hive partitions & buckets with example. hive bucketing is a way to split the table into a managed number of clusters with or without partitions.